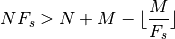Another representation of Frerking’s method¶
Frerking’s method is found in Frerking, M. E., Digital Signal
Processing in Communications Systems, Chapman & Hall, 1994, pp.
171-174. It is a method for creating a frequency-translating FIR filter
by translating the filter coefficients to a bandpass filter and then
convolving with the input samples (to simultaneously mix to baseband and
decimate). The method involves creating multiple bandpass filters so as
to maintain the linear phase property of the FIR filter. The number of
bandpass filters (sets of coefficients) required is defined as
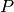 , and this value is also, therefore, the number of unique
, and this value is also, therefore, the number of unique
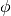 as shown below. The method can really be defined as doing
the following:
as shown below. The method can really be defined as doing
the following:
![\label{eq1}
{{b}_k[n]} = h[n]e^{j({\phi}_k + 2{\pi}n\frac{f}{{F}_s})}](_images/math/da155ebce130ea829078b691beea6756d7b3bd8b.png)
where 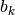 are the bandpass filters from
are the bandpass filters from 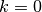 to
to
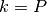 .
. ![{h[n]}](_images/math/b12a7c621de723ee6485072df2e6a2a7940fe992.png) is the original low pass filter coefficient
set of length
is the original low pass filter coefficient
set of length 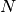 ,
, 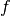 is the translation frequency, and
is the translation frequency, and
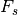 is the input sampling frequency.
is the input sampling frequency. 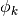 is the
starting phase of the NCO (numerically controlled oscillator) being
multiplied element by element with the low pass filter where
is the
starting phase of the NCO (numerically controlled oscillator) being
multiplied element by element with the low pass filter where
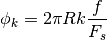
and where the minimum integer value is determined by the
equation given by Frerking:
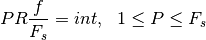
where 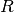 is the integer decimation rate. The maximum value of
would then be , assuming and
are integers.
is the integer decimation rate. The maximum value of
would then be , assuming and
are integers.
Then, to filter and decimate,
![{y[m]} = {y[Rl]} = \sum\limits_{n=0}^N x[Rl-n]{b}_{(n{\bmod}P)}[n]](_images/math/835c5a5cd22f152aa0d53a5a4e93efb2dbaddbf9.png)
where ![{y[m]}](_images/math/c53370222fa4ff30b1eea4e917fb17bc8723e2a2.png) is each baseband decimated sample, and
is each baseband decimated sample, and
![{x[l]}](_images/math/4de38b99ee191f10edcc833fd5bd26580294ec4e.png) is the input samples. By decimation, the output number of
samples,
is the input samples. By decimation, the output number of
samples, 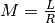 where
where 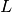 is the input number of
samples (although to avoid zero-padding for convolution,
is the input number of
samples (although to avoid zero-padding for convolution,
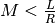 ).
).
Our new sampling rate will be
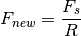
However, by using a single bandpass filter, a new method could be used. The starting phase of the NCO on the filter coefficient set is pulled out from the sum, and then phase correction is done on the decimated samples after the convolution step.
![{{b}[n]} = h[n]e^{j({2{\pi}n\frac{f}{{F}_s}})}](_images/math/345727c80e52731ff2858ebdb893ed49504da2bd.png)
![{y[m]} = {y[Rl]} = e^{j{\phi}_k} \sum\limits_{n=0}^N x[Rl-n]{b[n]},\ \ k = m{\bmod}P](_images/math/86c9c5b4bcd3336c637ca2631fc192da15fc5162.png)
Both methods are equivalent:
![e^{j{\phi}_k} \sum\limits_{n=0}^N x[Rl-n]h[n]e^{j(2{\pi}n\frac{f}{{F}_s})} = \sum\limits_{n=0}^N x[Rl-n]h[n]e^{j({\phi}_k + 2{\pi}n\frac{f}{{F}_s})}](_images/math/929039b6f4f6cef8a88e656ad1f86a69a93b8a44.png)
Frerking’s method requires 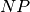 multiplications before
convolution, and for it to be most computationally efficient, it
requires storing sets of coefficients. For a small
value of and a large value of
multiplications before
convolution, and for it to be most computationally efficient, it
requires storing sets of coefficients. For a small
value of and a large value of 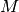 output samples, the
number of multiplications would be minimized by this method. However,
the worst case for using Frerking’s method is a large value of
,
output samples, the
number of multiplications would be minimized by this method. However,
the worst case for using Frerking’s method is a large value of
, 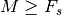 , and an unknown , meaning
that the storage requirements would be for
, and an unknown , meaning
that the storage requirements would be for 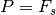 number of
sets of filter coefficients.
number of
sets of filter coefficients.
For the case when there exists a small value of or a large
value of or , the new modified method might be more
computationally efficient, as 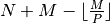 multiplications are
required in this method. However, the new method is more memory
efficient in all cases where
multiplications are
required in this method. However, the new method is more memory
efficient in all cases where 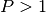 because only one set of
filter coefficients is required to be stored in all cases.
because only one set of
filter coefficients is required to be stored in all cases.
For an unknown integer value and an unknown decimation rate
(or where is not a submultiple of ), processing
would have to accommodate , and so Frerking would be
optimal where
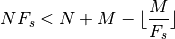
and the new method would be optimal for